![]()
|
|
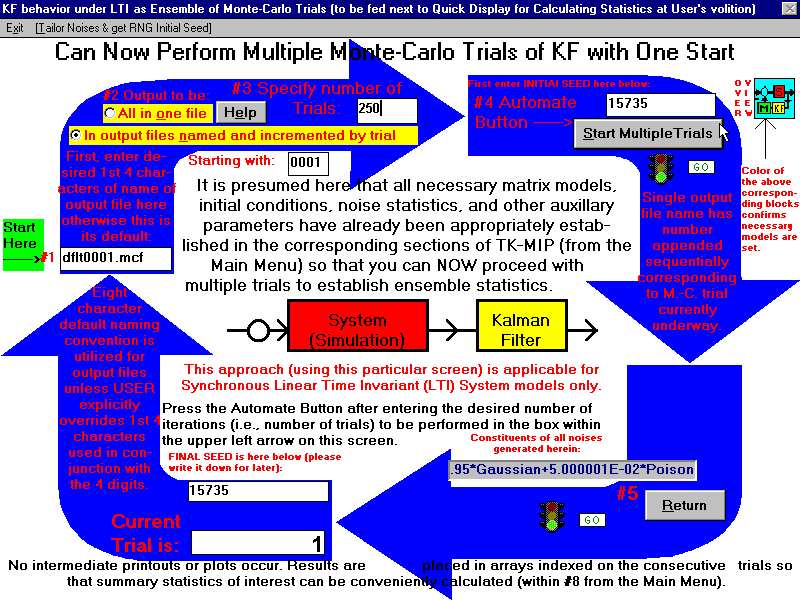
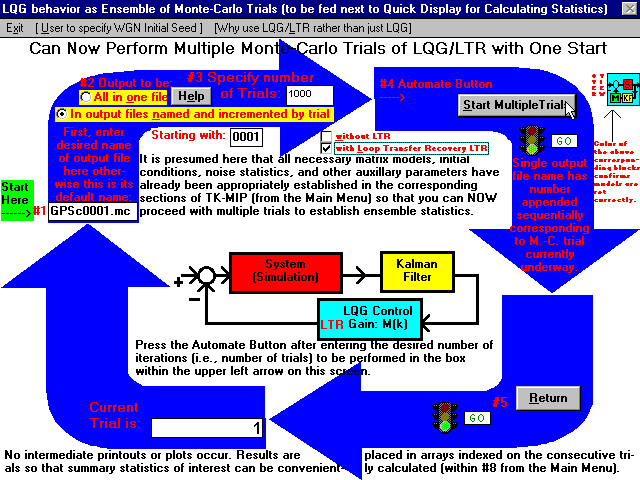
ScreenShot #5 (Merely a picture to illustrate that our GUI is totally self-explanatory)
For the two self-explanatory Monte-Carlo loops depicted in color above with detailed labels, the TOP LOOP is to be used for generating many Monte-Carlo trials (Item #3) of merely the ESTIMATOR alone; while the LOWER LOOP is to be used for generating many Monte-Carlo trials (Item #3) of the ESTIMATOR in CONJUNCTION with the LQG/LTR feedback within the loop to define the exogenous CONTROL inputted to the System Truth Model. For the cases considered for the LOWER LOOP, the models can ONLY be Linear Time-Invariant (LTI). The UPPER LOOP may be used for ANY of the ESTIMATORS considered or being handled herein [e.g., LINEAR Kalman Filter (KF), EXTENDED KALMAN FILTER (EKF), or GAUSSIAN SECOND ORDER FILTER (GAUSS 2nd ORDER FILTER)]. For both Monte-Carlo Loops depicted above, there are two conventions that may be used for the outputs of the trials, as selected by the USER in Item #2 before initiating the Trials by pressing the Start Button in Item #4. One convention is to generate the entire output time record for each individual underlying trial from START TIME to END TIME (being IDENTICAL for ALL "sample functions" as well as same underlying step-size "delta", Δ) using the unique USER supplied four character OUTPUT designator (case-sensitive) exclusively alpha filename inserted as Item #1. In the above example it is "GPSc". The numbers that follow are automatically generated internally and appended as part of the final 8 character filename to distinguish it as corresponding to each particular Monte-Carlo trial that is run, the first being "0001" (e.g., GPSc0001.mc). In this way, this Monte-Carlo section can automatically perform up to 9999 trials (a number that is probably larger than will ever be needed in practice). The file extension ".mc" corresponds to Monte-Carlo runs performed within this section in the manner described herein. While this approach can be applied to the case of a LINEAR Kalman Filter (KF), its real utility occurs when it is applied to an approximate nonlinear filter such as an EKF, or a GAUSS 2nd ORDER FILTER. Monte-Carlo simulations to test and prove the adequacy of these approximate filters in a tracking role is usually a mandatory goal. This approach can serve as an inventory of all trials generated (in case such evidence is needed later to demonstrate compliance to SOME, possibly imposed, specifications by being able to view individual "sample functions" residing in GPSc0001.mc, GPSc0002.mc, GPSc0003.mc,..., GPSc1000.mc, a requirement that is sometimes imposed for certain applications). [For this situation, one must tally statistics in a subsequent operation, either within TK-MIP or via an outside program operating on these files, such as MatLab for example or within Microsoft Access or EXCEL.] Alternatively, one can generate the statistical OUTPUT of ALL trials in one "feld swope" within TK-MIP so that the summarizing statistical output of everything is conveyed in a single time-indexed file. The single time-indexed file in this case contains a vector estimate, averaged over all N trials and a Matrix Covariance estimate, averaged over all N trials too. Such an Averaged output exists as a time series of the ESTIMATOR utilized (and its associated covariance matrix statistical estimate) over the specified time epoch encompassed from START TIME to END TIME, as computed at each intermediate time step provided in the original system specification, defined by the USER before entering this section for performing these Monte-Carlo calculations. [Subsequent clarification of our updated convention here: The two letter file extensions, discussed above for the two Monte-Carlo loops, eventually became the more conventional three letter extensions, as "*.mcf" for ESTIMATOR (or FILTER) and "*.mcc" for LQG/LTR feedback control, respectively.] The sequence or ORDER of calculating SAMPLE STATISTICS to be ultimately outputted: at each step-time of interest (that is fixed while the two statistics of interest are being computed), first calculate the SAMPLE MEAN across the ensemble of N-trials (by summing all N of the available variates and dividing this sum by N), then calculate the SAMPLE VARIANCE by subtracting this common SAMPLE MEAN, previously calculated (and now fixed) from each sample variate (double summed over all outter products, then dividing these appropriate sums by N-1) and output these two results being a VECTOR and a MATRIX, indexed on current time-step. Proceeding, in like manner, for each specified time-step of interest over the entire time epoch from initial START TIME to FINAL TIME. In concluding, one may also desire to compare these SAMPLE STATISTICS to a single TRUTH sample function consisting of what the TRUTH Model provides with all PROCESS NOISE and MEASUREMENT NOISE zeroed out (which is computationally accomplished by, respectively, making all the entries of the TRUTH MODEL's Q matrix zero and all the entries of the TRUTH MODEL's R matrix zero) for this one single run. [IMPORTANT: The FILTER MODEL's Q and R matrix are NOT correspondingly zeroed since they determine the impulse response behavior of the ESTIMATOR to this particular TRUTH MODEL stimulous as its input.] The measure of "dispersion", calculated as +/- the square root of each element on thhe main diagonal of the SAMPLE VARIANCE (now being the standard deviation), should reasonably bracket (perhaps by also using a convenient scalar multiplier [e.g., either 1 or 2 corresponding to 1-sigma or 2-sigma, respectively] throughout) to bracket by encompassing this single "special" TRUTH SAMPLE function and the SAMPLE MEAN. This would be the ultimate measure of utility of employing THIS ESTIMATOR for the application over this Time epoch. FURTHER CLARIFYING: this final view should be provided for each component of the underlying state vector to visually demonstrate the utility of this particular ESTIMATOR over the entire time epoch [i.e., from START TIME to END TIME] for this particular application. While we have already recounted the necessary steps to follow, as written down in English here, please now view the specifics presented mathematically, as documented in LaTeX, for greater clarity within our proposal to Boeing, located next before the image below, and, respectively, appearing in Eqs. (14), (15), (16), and (17) therein. There are other ways to proceed by using alternative figures-of-merit (FOM) to demonstrate the utility of a particular estimator in an application without revealing sensitive units (that may be an important issue for Classified applications). See an alternative figure-of-merit, FOM, (with specific units absent or obscurred) on pages 17, 18, 19, and 20 in our proposal to Boeing, as presented in the very next document just prior to the image. Please click on it now to verify that the information is indeed there, as advertised. Please see the following link for this useful alternative way that one may use to proceed: Click here to download a 654KByte pdf file consisting of a TeK Associates' proposal solicited by Boeing (specifically by Sohail Y. Uppal)
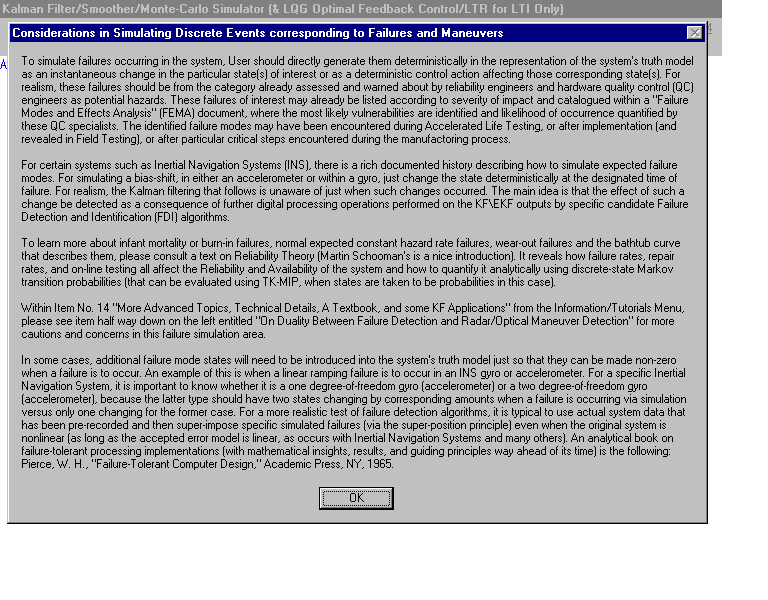
Prior Failure/Fault Detection Experience of TeK Associates personnel:
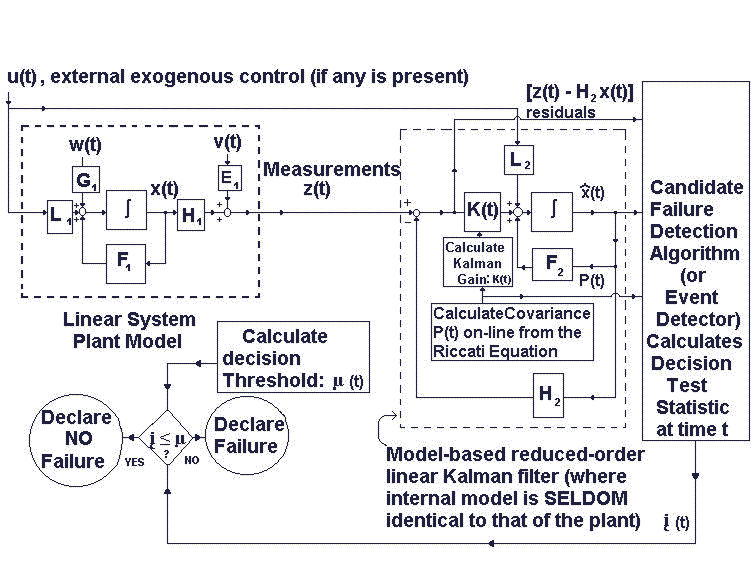
The approach developed above is independently endorsed in: Brumback, B. D., Srinath, M. D., “A Chi-Square Test for Fault-Detection in Kalman Filters,” IEEE Trans. on Automatic Control, Vol. 32, No. 6, pp. 532-554, June 1987. As can be seen from Ref. 25 of A. S. Willsky, "A Survey of Design Methods for Failure Detection in Dynamic Systems," Automatica, Vol. 12, pp. 601-611, 1976, my Two Confidence Region (CR2) predated Willsky's investigations. My even earlier "One Confidence Region" (CR1) approach to failure detection, took a geometric perspective of the underlying Gaussian Confidence Region but was NOT published in the open literature [but did use the same working tools exhibited in Earl D. Eyman and Thomas Kerr, "Modeling a particular class of Stochastic System," Int. J. of Control, Vol. 18, No. 6, pp. 1189-1199, 1973] but the specifics of my CR1 approach only appeared in a 1973 report to SP-24: Fagan, J., Kerr, T. H., and Uttam, B., “Poseidon Improvement Studies,” TASC Technical Report TR-315-1, Reading, MA, June 1973 (Confidential) for Navy, SP-24 of Strategic Systems Project office (Crystal City, VA), which Willsky was privy to, as a later TASC consultant, and which he rewrote as the several terms within double summations consisting of finite additions [all in just the same day that he was allowed to view this report]; however, Willsky gave it a different name: Weighted-Sum-Squared-Residuals (WSSR), although it appeared within my PL/1computer program implementation in Matrix Language 1 (ML/1) as exctly that when the quadratic forms were expanded out, and I immediately recognized the copying which had occurred). Please click this link: http://www2.econ.iastate.edu/classes/econ501/Hallam/documents/Quad_Forms_000.pdf, where the first line of Eq. 1 for an expression used for the CR1 (Ellipsoidal Confidence Region 1), where "Q" within CR1 is taken to be the symmetric (n x n) inverse of the positive definite covariance matrix for the n-dimensional random vector x, and the last line in this Eq. 1 is the double summation expression corresponding to what Alan S. Willsky used for what he renamed as WSSR. They are exactly equivalent expressions obtained merely by expanding it out as double summations representing the matrix products of my original (as also present in my ML/1 software implementation)!) This served as motivation for my later clarifications: (1) Kerr, T. H., “Examining the Controversy Over the Acceptability of SPRT and GLR Techniques and Other Loose Ends in Failure Detection,” Proceedings of the American Control Conference, San Francisco, CA, 22-24 June 1983; (2) Kerr, T. H., “Decentralized Filtering and Redundancy Management for Multisensor Navigation,” IEEE Trans. on Aerospace and Electronic Systems, Vol.23, No. 1, pp. 83-119, Jan. 1987; (3) http://ieee-aess.org/contact/thomas-kerr. My later response to: Brumback, B. D., Srinath, M. D., “A Chi-Square Test for Fault-Detection in Kalman Filters,” IEEE Trans. on Automatic Control, Vol. 32, No. 6, pp. 532-554, June 1987 pointed out that their suggested modification of my original CR2 failure detection technique, documented well before their modifications, would now have their suggested change in initial condition, as [ P_same-small | P_same-small ] |-----------------------|-----------------------| P_bigICmatrix = [ P_same-small | P_same-small ] , as their recommended initial condition to be used with their repackaging of my result that incorporates both my Ricatti equation and my Lyapunov equation into one larger augmented partitioned matrix equation. However, it is obvious from the structure of their augmented partitioned Covariance Initial Condition that they now recommend for starting the computations that it now lacks positive definiteness and will therefore cause severe numerical problems upon start-up. Acceptable initial conditions must at least be positive definite and (diag{P_same-small},diag{P_same-small}) should properly suffice. When I pointed out this crucial vulnerability or fatal flaw during my review and author's reply, they dismissed it with mere "lip service". The technical referee then nominated them for an award for my work that I had already clearly and adequately documented elsewhere: JOTA (1977), IEEE AC (1980), and IEEE IT (1982). They received the IEEE Control Systems award for MY work, which now had a fatal flaw in it, which they introduced.
A rigorous discussion on how one should handle repeated trials within simulations. Specifically, if one wants to generate an ensemble of sample functions representing several independent trials (that are later used to obtain sample statistics), one has to carefully manage the random number generators seed values. In the early to late 1970's, the random number generator was "RANDU" and it could be found within the standard FORTRAN Scientific Subroutines that all technologist had access to. Randu could be used to generate pseudo-random numbers within an interval corresponding to a uniform distribution and Analyst/Programmer supplied an initial seed (an odd number) and then (after each trial run over the time interval of interest) the Analyst/Programmer could retrieve the final value from RANDU (that would be used as the initial seed in the next run). This was coded up to be handled automatically for any large number of trials. The typical number of trials could be 100 or 200 in those days. [National Missile Defense's definition of "large number of trials" is usually 500 to 1000 sample trials (and maybe even more).] Although noise to be used within simulations was to be zero mean Gaussian White Noise with Specified constant variance, this was obtained from RANDU (with the same specified variance) in two different ways: (1) either as sum of 6 or more uniform variates, then normalized by dividing by 6, or (2) generated in pairs by taking variates from RANDU in pairs and applying sine and cosign and two square roots on them. Both approaches (and others) are discussed in Abramowitz and Stegun Handbook of Mathematical Functions (which, in those days, was available from the Government Printing Office for $6.00). The reason for handling in this manner, was that random number generators eventually repeat and are already selected based on computer register size and other number theoretic considerations to maximize the number of variates that it can generate before it repeats. That is why the same random number generator is used to generate all the initial values that are random, and the the process noises and the measurement noises, otherwise if three or more instantiations of a random number generator were started, there is a strong likelihood that results that should be independent would be correlated. Number theory says that they are, in fact, slightly correlated even when handled gingerly in this way. Randomly starting with different seed values on several different random number generators increases the odds of incurring correlation (from repeated sequences at different point in the cycle). That is why just one random number generated was used throughout and input and output seed carefully managed to avoid repeats and to maximize number of variates generated before any repeating occurs. MatLab, similarly offers access to the starting and ending seeds for the same tight control (for those who know why it is important). These days, other criticisms can be validly made about the "lack of true randomness" that is provided by most random number generators. For more discussion on this, please click on:http://www.tekassociates.biz/products.htm#RGNProblems.
All technologists should be aware of the “Gambler’s Ruin” problem. If unfamiliar, please “Google” it! https://en.wikipedia.org/wiki/Gambler%27s_ruin |
|
TeK Associates motto: "We work hard to make your job easier!" |